マイクロサービスを運用する際のテクニック
大規模なアプリケーションを可用性を保ちながら素早く進化させていくためにはマイクロサービスとして運用することが有用だとよく言われています。
マイクロサービスと聞くと、よく色々な書籍やサイトで説明されている設計論のようなものが思い浮かびます。
例えば、モノリスからどのようにマイクロサービスに移行するか、どのようにサービスを分割するか、データベースをどのように配置するかなどが良く語られている印象です。
実際にマイクロサービスを運用するにあたっては、それらのハイレベルな設計論に加えて、よく利用されるテクニックのようなものがあると思います。
その中の一つがリトライと冪等性です。
リトライ
リトライとは文字通り再試行することですが、ここでのリトライとは主にリクエストの再送信を意味しています。
マイクロサービスは一般的に、サービス間の通信をネットワーク上で行います。そのため、ネットワークの一時的な障害やサービスの一時的なダウンによってしばしばメッセージが欠落してしまいます。
その際の一つのハンドリング方法としては、エラーをupstreamのサービスにそのまま返却し、最終的にユーザーにもエラーを返すということが考えられます。この場合、ユーザーに手動でリトライしてもらう(GETならリロード、POSTならもう一度ボタンを押してもらうなど)ことを期待できますが、当然ながらユーザーが必ずそうしてくれる保証はありません。
アプリケーションの規模が大きくなっていくとマイクロサービスの数もどんどん増えていき、1つのユーザーリクエストを捌くだけでも数個から十数個のサービスを経由することも珍しくありません。そうすると、そのうちのどこかの通信でリクエストが欠落する確率は高くなっていきます。
そこで、各サービスが自動でリトライすることによってユーザーにエラーを返却することなく、リクエストを捌くことが可能になり、アプリケーションの可用性を担保することができます。
例えば、downstreamのサービスとの通信においてタイムアウトが発生した場合、特定のExceptionを投げるようにしておき、そのExceptionに対してリトライするよう設定することができます。
よくやる実装方法としては、リトライ可能(retryable)なExceptionはRetryableExceptionのようなインターフェースを実装してあげて、RetryableExceptionに対してリトライのハンドリングを追加する形です。
例として、JavaやKotlinなどでSpring Frameworkを使用している場合、Spring Retryを使うことで@Retryableというアノテーションを付与するだけで簡単に関数に対してリトライの設定をすることができます。
@Service
class Service {
@Retryable(retryFor = RetryableException.class)
public void service() {
// ... do something
}
}どのようなExceptionをリトライすべきかはアプリケーションやdownstreamのサービスによります。タイムアウトなどの一般的な場合に加えて、downstreamのサービスを管理しているチームとどのようなエラーコードの場合はリトライすべきかを事前に議論しておくと良いと思います。
また、リトライの上限回数を設定しておくことも大切です。無限にリトライしていると、ユーザーをその間ずっと待たせてしまうことになりかねないですし、リソースの観点からもあまりよくありません。
Exponential Backoff
リトライを等間隔で実行するよう設定していると、大量のリクエストが同時にリトライされdownstreamのサービスに大きな負荷をかけてしまうリスクがあります。
また、downstreamのサービスの一時的な障害でリトライが発生している場合、サービスが復旧するまでには一定時間かかるため、1秒間隔などでリトライしていても無駄なリクエストが多く送られてしまう可能性があります。
そこでよく導入されるのが、Exponential backoffというものです。これはリトライの間隔を固定値ではなく指数関数的に増加させ、またジッター(Jitter)と呼ばれるランダムな要素を加えることで、同時に大量のリクエストがリトライさせることを防ぐ手法です。
リトライ間隔は指数関数的に増えていくので、一度ダメだった場合は次のリトライはもう少し待つといった具合になり、サービスが復旧してからリトライしてくれる確率が上がったりします(もちろんこれは場合にもよります)。
Spring Retryであれば、@Retryableアノテーションのおいて簡単に設定することができます。
下記の場合、
といったタイミングでリトライが実行されます。
@Retryable(
retryFor = TimeoutException.class,
maxAttempts = 3,
backoff = @Backoff(delay = 500, multiplier = 2, random = true),
)非同期リトライ
上で説明したような同期的なリトライの場合、リトライしている最中はupstreamのサービスにはレスポンスを返さないので、ユーザーを待たせてしまうことになります。
アプリケーションによっては、必ずしも同期的に処理を行う必要はない場合があります。そこで非同期的なリトライを導入することも検討できます。
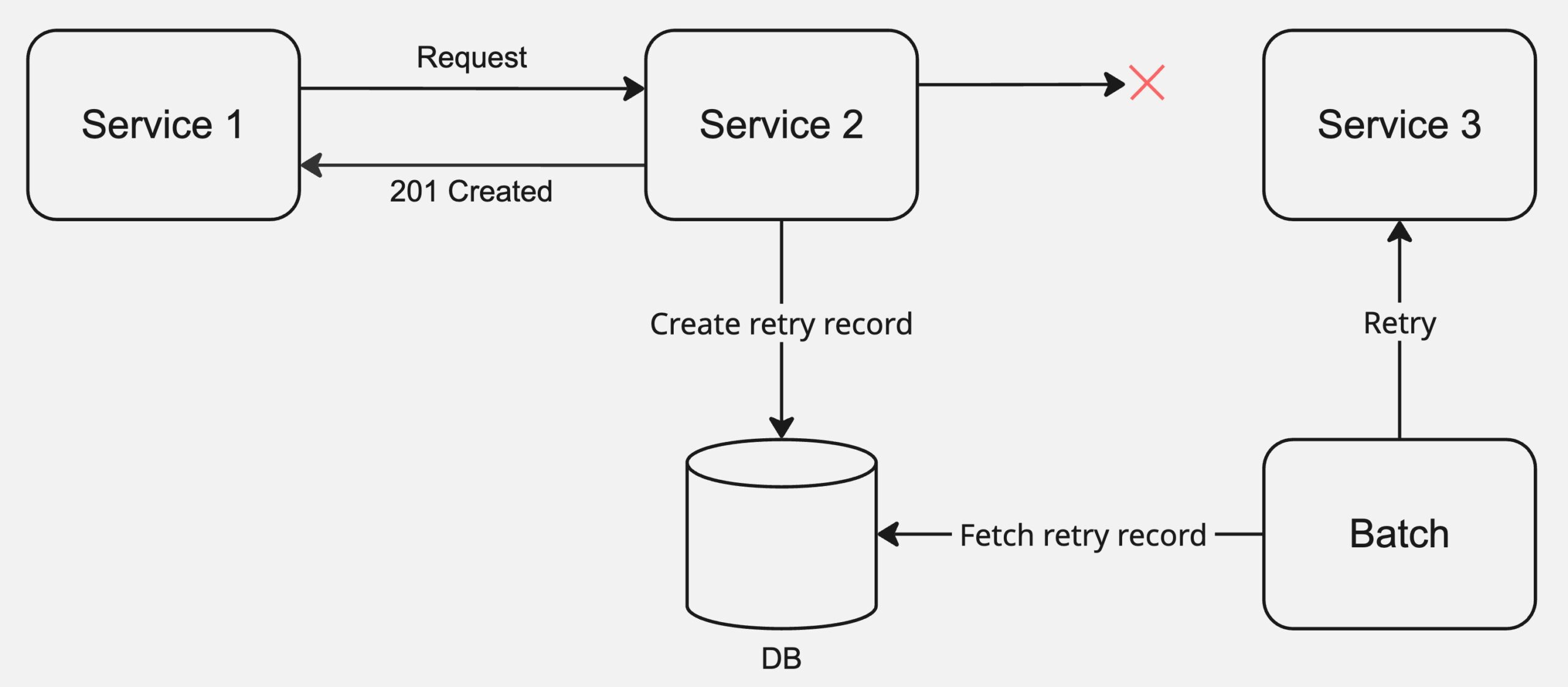
例えば、ECサイトで注文を行う場合を考えます。ユーザーは注文のリクエストを送り、サーバでは外部サービスに対して発注処理を行う時、retryableなExceptionが発生することがあります。その際、注文自体を失敗させる代わりに、upstreamサービスには201 Createdなどを返却し、ユーザーには注文は受け付けられたと通知することもできます。
その後、実際の発注処理はバッチ処理などの非同期な方法でリトライします。これによって、一時的な障害でユーザー体験を損ねることなく、可用性を担保することができます。
非同期リトライを実行する場合によくやる方法として、リトライテーブルのようなものを作成し、非同期リトライのリクエストが発生するたびにレコードを追加しておくことが考えられます。非同期のプロセスはこのリトライテーブルを参照することで、リトライのリクエストを生成してdownstreamサービスにリクエストを送ります。
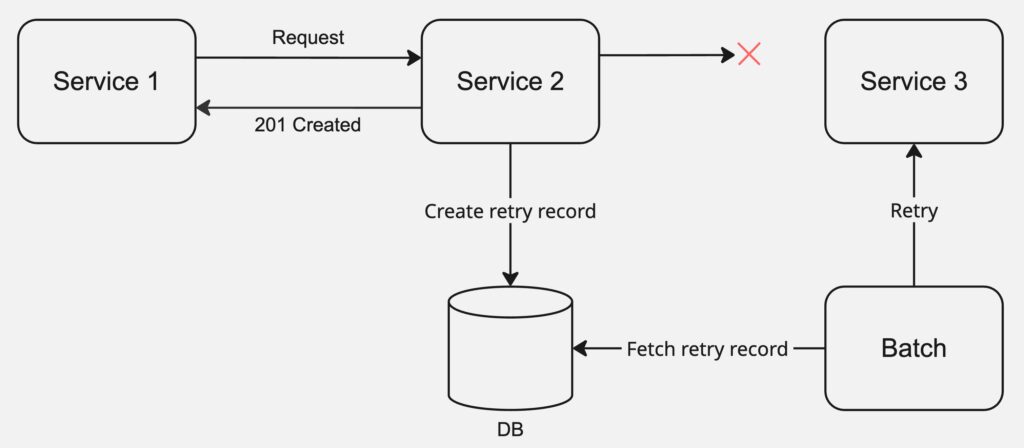
リトライに必要な情報(例 注文内容)はリトライテーブル自体に格納しても良いですが、元のテーブル(例 注文テーブル)に状態(例 processing, completed, failed)を持たせ、リトライ時は元テーブルを参照しつつ状態を更新するようにしても良いと思います。
もちろん、非同期リトライ中にリトライ不可能(non-retryable)なエラーが発生する可能性もあり、その場合は注文を失敗させる必要があり、そのケースも踏まえてUXやUIにおいてユーザーの期待値を調整することが重要になってきます(注文処理中から注文失敗になる場合もあるとわかるUX・UIにしておくなど)。
冪等性
リトライを実装する際は、1回目のリクエストがdownstreamのサーバに到達している可能性を考えることが重要になります。タイムアウトが発生する原因は多岐に渡りますが、例えばリクエストは到達して実際に処理されたが、レスポンスが欠落してしまったケースが考えられます。
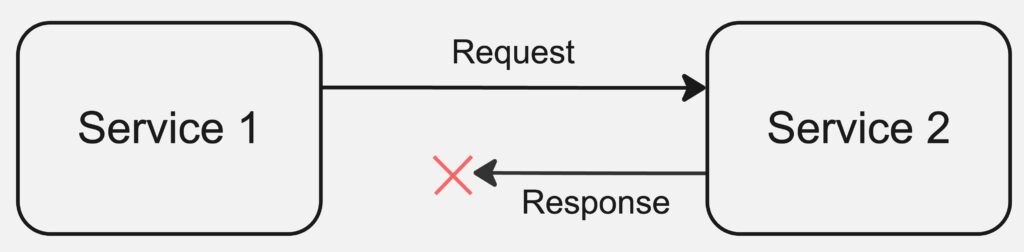
POSTなどのリソースを作成する場合や何かしらのトランザクションを実行する場合は特に注意が必要です。例えば、何かを注文するリクエストを送る場合、上記のケースでリトライをしてしまうとdownsteamのサービスにおいて同じものが2つ注文されてしまう可能性があります。
そこで、冪等性(idempotency)というものが重要になってきます。これは、
同じリクエストを何度送っても結果・状態が同じになる
という性質です。
POSTのリクエストにおいて冪等性を実装する際によく利用されるのが、何かしらの一意なキーをリクエストに追加しておくテクニックです。よくidempotent-keyなどと呼ばれますが、downstreamのサービスは実際のトランザクションを処理する前に、以前に同じidempotent-keyを処理したことがあるかを確認し、もしある場合はトランザクションを実行することなく以前と同じ結果を返すようにしたりします。
例えば上記の注文のケースを考えると、レスポンスとして伝票IDのようなものを返す場合、downstreamのサービスにおいてはidempotent-keyと伝票IDをデータベースなどで紐付けておき、リクエストを受け取ったらまずidempotent-keyがデータベースに含まれているかをチェックします。もしレコードが存在する場合は注文処理を実行することなく、取得した伝票IDを返却するようにします。
fun order(idempotentKey: String, order: Order): String {
val existing = orderRepository.find(idempotentKey)
if (existing != null) {
return existing.voucherId
}
// continue order transaction
}idempotent-keyは一意であれば基本的に何でもOKです。例えばUUIDなどがよく使われると思います。リクエストのボディに入れても良いですが、業務ロジックではないのでヘッダに入れたりもします。
また、upstreamのサービスからidempotent-keyが送られてきており、さらにdownstreamのサービスにリクエストを送る場合、そのままforwardしても良いですし、新しくidempotent-keyを生成しupstreamサービスからのidempotent-keyと紐付けて保存しておくのもありだと思います。この辺りはサービスやチームによって自由です。
まとめ
マイクロサービスにおいて、自動リトライを実装しておくと一時的なネットワークやサービスの障害に対して可用性を上げることができます。
リトライする際には冪等性を考慮しておくことが大切で、idempotent-keyなどをリクエストに含めることでそれを担保することができます。

コメント